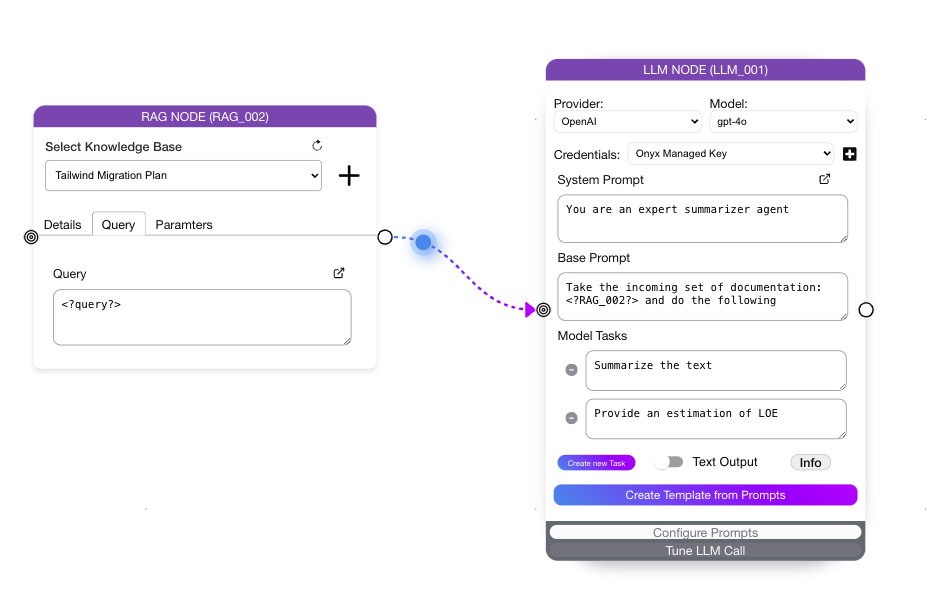
Creation
Choose your Vector Database and corresponding RAG metrics
RAG metrics include the embedding model, Vector Space, Similarity Metric, and metadata values to be included
Usage
The RAG node will be responsible for Embedding incoming queries and performing simalirty search to retrieve relevant documenation. This can be passed to an LLM node for further processing/inference.Input Query
This can be paramaterized (for example if you want to pass in a query from your front end:)
- Denote Variable: < ?input_query? >
- Input Query will be embedded and semantic search will take place
- Relevant documents returned